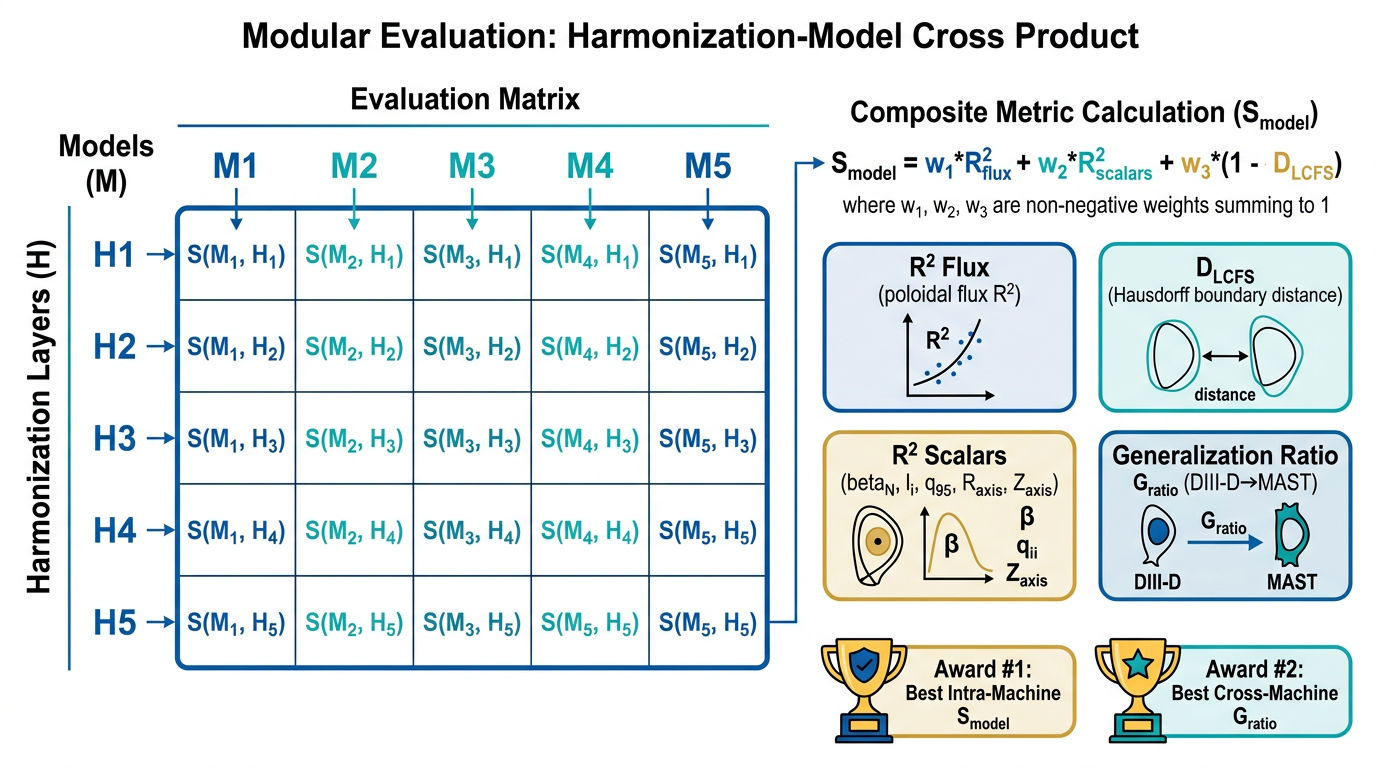
How submissions are scored
Three complementary metrics combine into a single composite score, with a separate cross-machine generalization award and a harmonization quality gate.
What we measure
Flux accuracy
Coefficient of determination of the predicted flux map over all grid points, timesteps, and test shots. The primary signal of reconstruction quality.
Scalar fidelity
Mean R² across the five scalar equilibrium parameters — βN, li, q95, Raxis, Zaxis.
Boundary alignment
Symmetric Hausdorff distance between predicted and true last-closed-flux-surface contours, normalized by the true LCFS major radius. Smaller is better.
Composite & generalization
Composite score S_model
S = 0.6·R²ψ + 0.25·R²ₛ + 0.15·(1 − D_LCFS)
A weighted blend in [0, 1]. R² terms are clipped at 0 and D_LCFS at 1. The highest
S_model on the hidden DIII-D test set wins Award #1.
Generalization ratio G_ratio
G = S_model(MAST) / S_model(DIII-D)
The fraction of DIII-D performance retained under zero-shot transfer to MAST. Values near 1 indicate near-complete
transfer. Admissibility gate: R²ψ > 0.6 on DIII-D.
Quality gate & submission format
Harmonization quality gate
τ_H = 0.90): required variables present,
time-aligned, unit-consistent, and artifacts that regenerate identically under a clean rebuild
(SHA-256 match). Failing entries stay on the leaderboard but are ineligible for awards.
Submission format
.npz or NetCDF4 indexed by record ID and EFIT timestamp, plus a manifest naming the
harmonization layer. Scoring runs CPU-only in under five minutes per pass.
Development, then a blind final
Phase 1 — development
~3 monthsPhase 2 — final
BlindRules & eligibility
- 1 Each team registers on Codabench with a single valid contact email; aliases that already exist as solo participants are deactivated.
- 2 External public datasets (other tokamak archives, OMFIT-produced equilibrium tables) and publicly available pre-trained vision or scientific foundation models are permitted, with explicit disclosure in the methods report.
- 3 No restriction is placed on programming language or framework.
- 4 All train/test splits must respect shot-level boundaries.
- 5 Harmonization layers must regenerate deterministically under a clean rebuild (SHA-256 hash match).
- 6 Top three teams in each award category must release source code under an OSI-approved licence and submit a 1–2 page methods report before prizes are paid.
- 7 Organizing-team members with access to the hidden ground truth are excluded from prize eligibility.
- 8 All participants follow the NeurIPS Code of Conduct.